Det viktigaste vi har i en IT-organisation är vår IT-miljö. Det är med hjälp av den som IT-tjänster produceras och tillför nytta till verksamheten. Om IT-miljön skulle sluta att fungera stannar IT-tjänsten och då har verksamheten ingen nytta av IT-organisationen.
Det är med det perspektivet som IT-organisationen behöver en snabb och väl intrimmad process för att återställa fel som uppstår i IT-miljön. Om något inte fungerar av det IT-organisationen har lovat i överenskommelser med verksamheten så finns det just då ingenting som är viktigare.
En grundförutsättning för att incident management-processen ska fungera är att tydliga överenskommelser finns. Att det är helt klart vad som ska fungera och inte. Risken finns annars att processen fylls med ärenden som inte är direkt kopplade till ett fel i IT-miljön. IT-organisationen vänjer sig då med ett konstant flöde av incidenter och kopplingen till att incidenter är viktiga försvinner.
En incident definieras som:
”En incident är ett oplanerat avbrott eller en försämring i kvaliteten av en IT-tjänst. Ett fel på en komponent i IT-miljön som inte direkt påverkar kvaliteten i leveransen (till exempel en hårddisk med redundans) ska också klassas som en incident.”

Syfte
Huvudsyftet med incident management-processen är återställa överenskommen servicenivå så fort som möjligt och att minska de negativa konsekvenserna för verksamheten. Detta innebär att om IT-organisationen inte har möjlighet att åtgärda felet direkt kan en temporär lösning (Eng. workaround) som återställer funktionaliteten för användaren vara tillräcklig. Syftet innebär även att en incident ska åtgärdas så långt det är möjligt på ett sådant sätt att verksamheten inte ytterligare påverkas negativt.
Syftet med incident management uppnås genom att:
- Säkerställa att standardiserade metoder och rutiner används
- Göra incidenter synliga internt och hos verksamheten
- Agera professionellt genom att kommunicera och lösa incidenter snabbt när de uppstår
- Utgå från verksamhetens prioriteringar vid prioritering av incidenter
Omfattning
Ordet incident betyder ”oväntad, störande händelse”. En översättning av incident management blir då ”hantering av oväntade, störande händelser”. Detta betyder att förväntade, störande händelser inte omfattas av incident management-processen.
För att sätta en tydlig gräns på vilka störningar som kan förväntas och inte så regleras detta av den dokumentation som tas fram i release management-processen. Under testningen av releaser som driftsätts ska fel som upptäcks dokumenteras som kända fel. Denna dokumentation av kända fel används sedan som definition på vad som är oväntat eller förväntat. Det betyder att om ett av en användare anmält fel finns registrerat i listan av kända fel så ska ärendet inte betraktas som en incident. Skillnaden mellan ärendetyper och hur dessa ska hanteras finns beskrivet närmare i kapitlet om service desk-funktionen.
Alla incidenter i IT-miljön, oberoende av vem som upptäcker dem, omfattas av incidentprocessen. Alla incidenter som påverkar leveransen av IT-tjänster, oavsett vem som producerar tjänsten, ska omfattas av incidentprocessen. Det innebär att ett fel som uppstår hos en leverantör, som i sin tur påverkar leveransen av IT-tjänster, ska även det betraktas som en incident.
Värde för verksamheten
Incident management-processen brukar vara en av de första och mest uppmärksammade processerna som etableras. Anledningen är den tydliga kopplingen mellan snabb hantering av fel i IT-miljön och nytta för verksamheten. Mer specifikt bidrar processen med:
- Möjligheten att snabbt spåra och lösa incidenter i IT-miljön minskar påverkan på verksamheten och bidrar till ökad produktivitet hos kunden.
- Möjligheten att prioritera mellan olika samtidiga fel enligt vad som är viktigast för verksamheten bidrar till ökad produktivitet i viktiga funktioner.
- Möjligheten att identifiera förbättringsmöjligheter, till exempel utbyte av gammal och instabil hårdvara, kan öka produktiviteten hos kunden.
Prioriteringsmodell
Det är bra att använda en gemensam modell för prioritering oavsett ärendetyp. Det förenklar arbetet för den som ska prioritera och det minskar risken för missförstånd när ärenden skickas mellan olika delar av IT-organisationen.
Oavsett ärende så är första frågan vilken påverkan ärendet har för verksamheten just nu. Frågan besvaras med antingen hög som betyder att verksamheten inte kan fortsätta om ärenden inte hanteras, medel som betyder att verksamheten kan fortsätta med besvär eller låg som betyder att verksamheten kan försätta utan besvär.
Därefter ställs frågan om vilken påverkan ärendet har för verksamheten inom överskådlig framtid enligt samma kriterier. Svaret på den frågan är ofta ett annat än svaret på frågan om påverkan just nu. Till exempel kan ett ärende som inte är tidskritiskt just nu få verksamheten att stanna om ärendet inte är löst om en månad.
Den tredje parametern är tidsramen för framtida påverkan. Den ska beskrivas som en tidsangivelse då ärendet senast måste påbörjas.

Prioriteringen görs sedan som en sammanlagd bedömning av nuvarande och framtida påverkan.

Prioriteringsnivån baseras med tyngdpunkt på nuläget. Det är därför viktigt att nuvarande och framtida påverkan beskrivs som text i ärendet så att alla ärenden löpande kan omprioriteras efter hand som tiden går. Här kan även tidsramen användas som flagga för omprioritering. Denna modell ger tillräckligt med information för att hantera omprioriteringen och även ett bra underlag om ärendet ska skickas vidare till en annan enhet inom eller utanför IT-organisationen.
Major Incident
Service desk-funktionen som huvudsakligen hanterar incidenter är optimerad för genomströmning. Incidenter ska lösas så fort som möjligt och handläggarna i service desk ska kunna hantera många ärenden per arbetspass. Därför finns det anledning att ha en separat rutin för incidenter som är av sådan storlek eller har sådan påverkan att de kräver all uppmärksamhet från IT-organisationen under hela incidentens livscykel. Sådana incidenter klassificeras som major incidents.
En major incident ska ha en separat fördefinierad rutin med snabbare eskaleringsvägar och större beslutskraft. Rutinen ska ha en väl definierad trigger som kopplas in i incidentprocessens prioritering. Ett separat team för lösning av incidenten bör sammankallas och innehålla:
- Incident manager
- Problem manager
- Tjänsteansvarig
- Systemspecialist och/eller tekniker
- Dokumenterare
- Kommunikatör
Även om lösningen på incidenten är uppenbar så ska ett problemärende skapas för att förhindra att incidenten återkommer. Ärendet ska hållas avskilt under hela incidentens livscykel så att det inte riskerar att fördröja lösningen. En major incident ska alltid avslutas med en utvärdering av arbetet så att rutinen kontinuerligt förbättras.
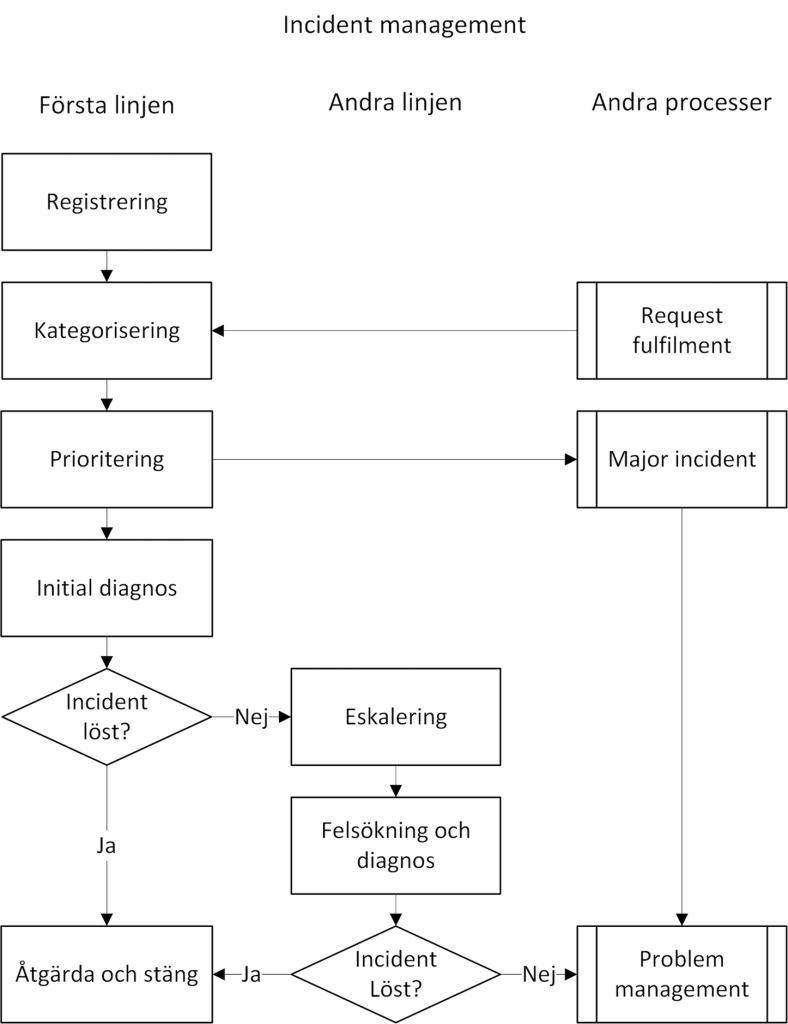
Aktiviteter
Följande aktiviteter finns i incident management-processen. Om ärendet kommer in till service desk via en användare så hanteras de första två aktiviteterna (registrering och kategorisering) i request fulfilment-processen.
Registrering – Alla ärenden måste registreras med berörd användare, utrustning och en utförlig beskrivning av ärendet. Det är oftast i det här statusläget som automatgenererade incidenter via larm hamnar där en handläggare kan ta vid och komplettera informationen. Om ett ärende skickas vidare till en annan grupp/organisation för vidare undersökning underlättas arbetet väsentligt när bra och komplett information är inskriven i ärendet.
Kategorisering – Kategorisera ärendet enligt en fördefinierad lista. Kategoriseringen är samma oavsett ärendetyp och speglar tjänstekatalogens uppbyggnad för att bland annat underlätta ansvarsfrågor och statistik.
Prioritering – Prioriteten avgörs genom att en kombination av nuvarande påverkan, framtida påverkan och tidsram enligt prioriteringsmodellen.
Initial diagnos – Supportteknikern försöker direkt att lösa incidenten med hjälp av egen kunskap eller dokumentation i tidigare registrerade incidenter, problem och kända fel och därefter stänga ärendet. Om en direkt lösning är omöjlig ska incidenten eskaleras vidare.
Eskalering – Eskalering till andra linjens support inom service desk eller en extern leverantör kallas för funktionell eskalering. Ibland kan en incident behöva mer beslutskraft för att lösas, så kallad hierarkisk eskalering. Exempel på det kan vara omstart av en gemensam funktion eller en ominstallation som kräver tillstånd.
Felsökning och diagnos – Andra linjens support har oftast inte användaren i luren och kan då lägga mer tid och kraft på att lösa incidenten. Grundregeln är att incidenten ska kunna lösas med hjälp av dokumentation och egen kunskap men vanligtvis sätts även en tidsgräns som är kopplad till prioriteringen för hur länge arbetet med felsökning av en incident får fortgå innan ett problem ska skapas.
Skapa ett problemärende – Om inte andra linjen kan lösa incidenten inom angiven tid så ska ett problemärende skapas. Incident manager bör involveras för att eventuellt besluta om att även höja prioriteringsnivån till major incident.
Åtgärda och stäng – Alla lösningsgrupper kan stänga ett ärende efter att ha kontrollerat med användaren att funktionen är återställd. Om det krävs en förändring i IT-miljön för att åtgärda incidenten ska change manager kontaktas för att genomföra en akut förändring i IT-miljön.
Dokumentation
Följande dokumentation ska finnas inom ramen för incident management:
- Historik över tidigare incidenter innehållande:
- Datum och tid
- Namn på handläggare
- Beskrivning av symptom
- Åtgärder
- Incidentkategorier
- Major incident-rutin
- Incidenttyper med förslag på lösning
- Kontaktuppgifter till interna och externa lösningsgrupper
- Prioriteringsmatris
- Beskrivning av påverkan för varje IT-tjänst
Relationer till övriga processer och funktioner
Incident management-processen har kopplingar till många andra processer. Här listas de vanligaste:

Trigger
Incident management triggas genom att:
- En användare kontaktar service desk om ett fel
- Ett system automatregistrerar ett fel
- Någon på IT-avdelningen upptäcker ett fel
- En leverantör kontaktar IT-organisationen om ett fel
Input
Följande input behövs för incident management:
- Dokumentation om alla IT-tjänster och dess tillhörande komponenter
- Information om kända fel och temporära lösningar
- Information om tidigare incidenter
- Information om genomförda ändringar i IT-miljön
- Överenskomna servicenivåer på IT-tjänsterna
- Dokumenterade kriterier för prioritering och eskalering
Output
Följande output genereras av incident management:
- Lösta incidenter
- Uppdaterad dokumentation om genomförda aktiviteter kopplade till incidenten
- Kategoriserade incidenter för vidare analys av problemprocessen
- Registrerat problemärende
- Återkoppling till change management-processen för incidenter kopplade till en förändring
- Information och statistik över incidenter
Mätning
Så här kan incident management-processen mätas:
- Genomsnittstid för att lösa incidenter
- Genomsnittstid av lösningstiden som utförs av externa grupperingar
- Tid mellan incidenter på samma tjänst, system eller komponent
- Antal öppna incidenter
- Nedlagd genomsnittstid per incident
- Antal och procent av totalen som
- stängs vid initial diagnos
- klassificeras som major incident
- är felaktigt eskalerade
- är felaktigt kategoriserade
- hanteras inom avtalad tid och servicenivå
Utmaningar
En av de svåraste utmaningarna med incident management är att hålla processen ren från övriga ärenden som inte är oväntade störningar i IT-miljön. Det krävs tydliga riktlinjer för vad som är en incident och kontinuerlig uppföljning av de medarbetare som registrerar incidenter.
Det är inte ovanligt att incidenter med låg prioritering blir liggande i veckor eller till och med månader långt ner i någons ärendehög. Ett sätt att motverka detta är att avsluta incidentärendet och istället registrera ett problemärende. Då kommer ärendet att hamna i den gemensamma prioriteringen för kontinuerlig förbättring. Om felet kvarstår i IT-miljön kommer framtida ärenden att kopplas mot det registrerade problemärendet och prioriteringen kommer att höjas.
Det är viktigt för incident management-processen att dokumentationen av kända fel i release management-processen fungerar. Annars riskerar IT-organisationen att få incidenter registrerade på befintliga och redan kända fel.
Följande moment behöver dessutom särskild uppmärksamhet vid införande av processen:
- Förmågan att upptäcka incidenter så tidigt som möjligt
- Få samtliga handläggare som arbetar i processen att följa rutinerna och dokumentera alla incidenter som uppstår
- Åtkomst till information som behövs för att snabbt lösa incidenter.
- Tillgång till kunskap och dokumentation av IT-miljön
- Koppling till verksamheten och dess krav på prioritering
