Many IT organizations find it difficult to distinguish between incidents and problems. Technical analysts and applications analysts are inquisitive by nature, which results in the underlying problem for each incident being investigated and becoming resolved. As investigating each problem requires resources, and resources cost money, in the worst case there are several problems which should not have been resolved due to the fact that in a larger perspective these resources should have been prioritized differently.
Problems that are investigated by individuals are usually resolved through personal knowledge and experience. Unfortunately, this knowledge and experience can be a limitation if the problem is complex and several different areas are involved. What is needed then is a more extensive investigation and a proven method to find the fundamental cause. Otherwise there is a risk that the problem will remain unresolved for a substantial period. Using Problem Management as a separate process ensures that the IT organization has control over existing problems and can prioritize which should be investigated as well as ensure that proven tools and methods are used for complex problems.
A problem is defined in this book as ”the unknown underlying cause that something has occurred”.
Purpose
The main purpose of the Problem Management process is to reduce the number of recurrent incidents in the IT environment and the negative impact they have.
The purpose of Problem Management is achieved through:
- Preventing incidents from arising through rectifying the basic cause
- Minimizing the negative impact on the business from incidents which cannot be prevented
Scope
A problem is the unknown cause that something has happened. It is not restricted solely to the IT environment. As the process has the tools required, it can also be used to resolve problems which have arisen elsewhere in the IT organization.
The Problem Management process comprises the tools and activities that are required to find the fundamental cause that something has occurred, and defines which measures are required to rectify the problem.
The process also comprises implementing the solution according to relevant procedures. Specifically, those included in the Change Management and Release Management processes. The scope also includes providing a list of known errors and temporary solutions for the rest of the IT organization.
Value for the business
The Problem Management process is probably one of the most profitable processes for the business as it reduces the number of incidents in the IT environment. The process also reduces the time for major incidents and ensures that they do not arise again, thus minimizing production losses. The list of known errors and temporary solutions provides Service Desk with the prerequisites to resolve issues more quickly, thus reducing the time taken up by disturbances in the business. Furthermore, the process enables the business to prioritize which problems should be investigated and thus select how resources are prioritized.
Reactive and proactive problems
Reactive problem records are incidents which first or second line support have not succeeded in resolving. In other words, there is an ongoing disturbance in the IT environment which means that this type of problem is urgent until a temporary solution has been found and the incident is resolved.
Proactive problems are all other problem records. These are usually registered on the basis of recurrent incidents where the cause is unknown, but it can also be individual events where the cause needs to be identified. Proactive problems cost time and money to resolve. These needs are prioritized together with all other issues within the IT organization, which means that they should be managed by the concerned function in Continual Service Improvement.
Known errors and temporary solutions
Not all problems in the IT environment have to be resolved. There might be various reasons: for example, that a new release is planned within the near future which will resolve the problem anyway, or that the cost of investigating or resolving the error is so high that the business feels it is not worth it. Regardless of reason, the error should be described and stored in a database or in a document so future issues received can be linked to an error already known.
There should be a temporary solution for each known error. This usually consists of instructions which enable users to work around the error in the IT environment and thus continue working. In certain issues, the temporary solution may be to inform the user that there is an error and that the customer has decided not to do anything about it. Examples of this might be minor bugs in an application which are detected in connection with deployment, but nevertheless approved by the customer.
Used optimally, the list of known errors is a complete record of all errors in the IT environment. The list is an invaluable aid for Service Desk in ensuring that time is not put unnecessarily into errors which have already been identified. The list also functions as an input for Continual Service Improvement of the services.
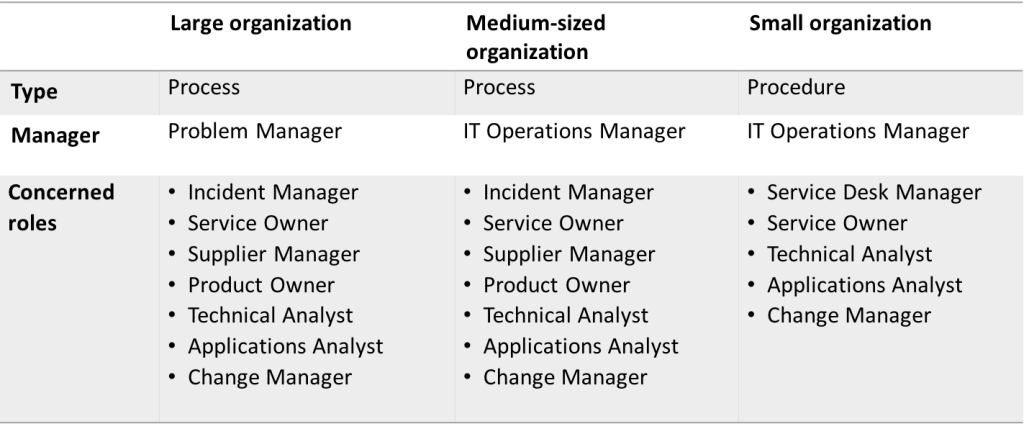
Activities
The following activities are included in the Problem Management process. The activities are fundamentally the same for both proactive and reactive problem records. The difference is that reactive problems have to be resolved under time pressures until a temporary solution is found which works.
Registration – All issues must be registered with concerned user, equipment and a detailed description of the issue. If an issue is sent onward to another group/organization for further investigation, the work is made considerably easier when effective and complete information is entered in the issue.
Categorization – Categorize the issue according to a predefined list. The categorization is the same regardless of type of issue, and it reflects the service catalogue’s structure in order to facilitate, among other things, responsibility issues and statistics.
Proactive or reactive problem – Proactive problem records are sent to the function concerned via the Continual Service Improvement process, where a decision is taken on whether the problem should be resolved or not. Reactive problems proceed to problem solving.
Problem solving – For reactive problems, the primary task is to find a temporary solution so that the incident can be closed. The activity subsequently entails identifying the cause of the problem and finding a solution. For complex problems, a proven model should be used, Kepner-Tregoe for example.
Change in the IT environment (RFC) – Solutions which require a change in the IT environment should be managed via the Change Management process.
Resolution – Implement the solution for the problem.
Check functionality – Check that the problem is resolved and institute the measures required to ensure that the problem does not arise again.
Close – Check all documentation concerning the issue and conclude.
Documentation
The following documentation should be included within the framework of Problem Management:
- Known errors including temporary solutions
- Model for problem solving
Relationships with other processes and functions
The Problem Management process has links to many other processes. The most common are listed here:

Trigger
Problem Management is triggered through:
- An incident that cannot be resolved by the second line through documentation or knowledge
- A problem identified when reviewing trend reports and statistics
- One or a number of incidents which have the same fundamental, unknown cause
- A proactive problem that is identified by someone in the IT organization
Input
The following Inputs are needed for Problem Management:
- Documentation of incidents
- Information about products and components in the IT environment
- Model and tools for problem solving
Output
The following outputs are generated by Problem Management:
- Resolved problems
- New or updated documentation
- Change request to the Change Management process
- Temporary solutions for incidents
- New or updated known errors
- Problem reports
Measurement
The Problem Management process can be measured through:
- The number of known errors added to the documentation
- Number or percentage of:
- Incorrectly registered problems
- Incorrectly categorized problems
- Average resolution time for incidents linked to a reactive problem
- Average cost per problem
- The number of issues resolved with the help of a known, documented error
- The total number of incidents
Challenges
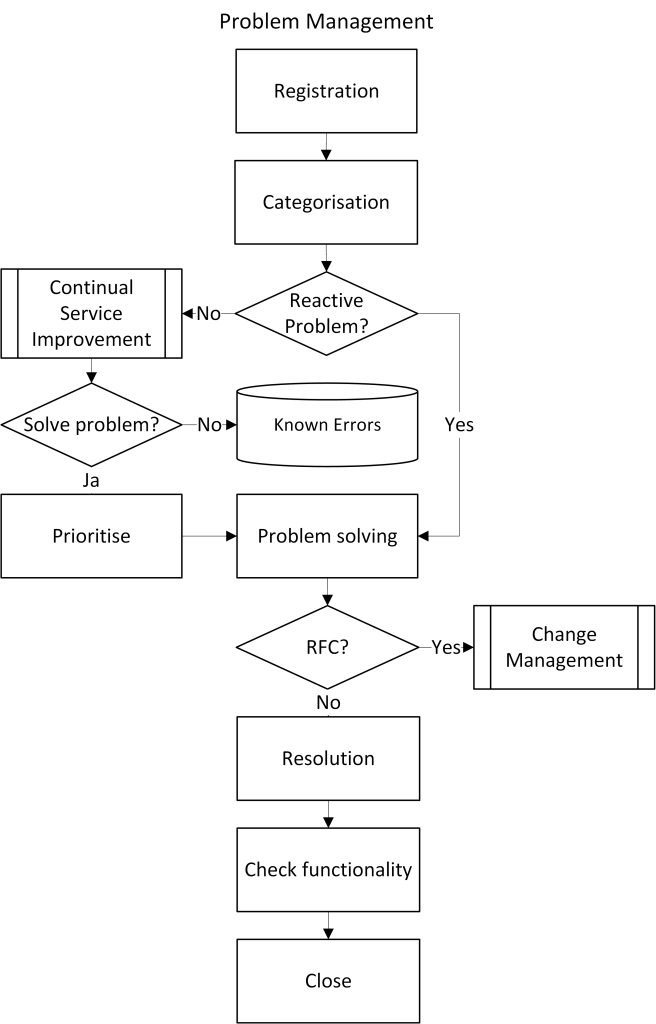
Many IT organizations find it difficult to distinguish between the management of incidents and the management of problems. There is however a major difference in who should manage the issue. For incidents, this is dealt with by Service Desk and in certain issues also by an incident manager, normally without the service owner needing to get involved.
For problem records, it is the reverse. The issue should be owned and managed by the respective service owner. Avoid making Problem Management an operational function which, without the service owner’s involvement, is expected to manage all issues. The consequence of this is that in the worst case the whole purpose of overall prioritization disappears. Furthermore, it becomes difficult to finance the process unless the costs can be linked to the service being investigated.
In addition, the following elements need particular attention when implementing the process:
- An effective and well-established incident process
- Improve technical analysts’ analytical ability and knowledge concerning error location
- Ensure that technical analysts have access to all documentation, all tools and all information necessary.
- Possibility of linking issues to known errors in the tool
